London Bikes Analysis

Analysing Excess rentals in TfL bike sharing
Let us call the latest data for bikes being hired every single day
url <- "https://data.london.gov.uk/download/number-bicycle-hires/ac29363e-e0cb-47cc-a97a-e216d900a6b0/tfl-daily-cycle-hires.xlsx"
# Download TFL data to temporary file
httr::GET(url, write_disk(bike.temp <- tempfile(fileext = ".xlsx")))## Response [https://airdrive-secure.s3-eu-west-1.amazonaws.com/london/dataset/number-bicycle-hires/2022-09-06T12%3A41%3A48/tfl-daily-cycle-hires.xlsx?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAJJDIMAIVZJDICKHA%2F20220919%2Feu-west-1%2Fs3%2Faws4_request&X-Amz-Date=20220919T190658Z&X-Amz-Expires=300&X-Amz-Signature=9143cdc9d6e825e159f7782e0306721a32093aedabd577c06b99d491f327107c&X-Amz-SignedHeaders=host]
## Date: 2022-09-19 19:11
## Status: 200
## Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
## Size: 180 kB
## <ON DISK> C:\Users\Dhruvi\AppData\Local\Temp\RtmpiwFibR\file4848a3b7565.xlsx# Use read_excel to read it as dataframe
bike0 <- read_excel(bike.temp,
sheet = "Data",
range = cell_cols("A:B"))
# change dates to get year, month, and week
bike <- bike0 %>%
clean_names() %>%
rename (bikes_hired = number_of_bicycle_hires) %>%
mutate (year = year(day),
month = lubridate::month(day, label = TRUE),
week = isoweek(day))Let us calculate the expected number of rentals per week or month between 2016-2019 and then, see how each week/month of 2020-2022 compares to the expected rentals. We will define excess_rentals = actual_rentals - expected_rentals`.
We should use the mean to calculate expected rentals. This is to maintain consistency with the mean actual rentals for 2020-2022 that we will use in comparison to the expected values.
# Create expected monthly bike rental by averaging monthly data from 2016-2019
expected_monthly_rental_summary <- bike %>%
filter(year >= 2016 & year <= 2019) %>%
group_by(month) %>%
summarise(expected_rental_mean = mean(bikes_hired, na.rm = TRUE))
# Create actual monthly bike rental data from 2017-2022
monthly_summary_17_22 <- bike %>%
filter(year >= 2017) %>%
group_by(year, month) %>%
summarise(monthly_mean = mean(bikes_hired))
# Join both tables
monthly_full_summary <- monthly_summary_17_22 %>%
left_join(y = expected_monthly_rental_summary, by = "month")
# Plot monthly changes in bike rentals faceted on year
ggplot(monthly_full_summary) +
geom_line(aes(x = month, y = monthly_mean, group = year), colour = "black", show.legend = FALSE) + #Line created for actual bike rental
geom_line(aes(x = month, y = expected_rental_mean, group = year), colour = "blue", size = 1.2, show.legend = FALSE) + #Line created for expected bike rental
facet_wrap(~ year) +
geom_ribbon(aes(x = month, ymin = monthly_mean, ymax = pmax(monthly_mean, expected_rental_mean), group = year, fill = "red"), alpha = 0.3, show.legend = FALSE) + #Ribbon created for expected>actual
geom_ribbon(aes(x = month, ymin = expected_rental_mean, ymax = pmax(monthly_mean, expected_rental_mean), group = year, fill = "green"), alpha = 0.3, show.legend = FALSE) + #Ribbon created using actual>expected
scale_fill_manual(values=c("green", "red"), name="fill") + #change colour fill of ribbons
labs(title = "Monthly Changes in TfL bike rentals", subtitle = "Change from monthly average calculated between 2016 annd 2019", x = "Month", y = "Bike Rentals") +
theme(plot.title = element_text(size = 14, hjust = 0.5),
plot.subtitle = element_text(size = 12, hjust = 0.5),
axis.title = element_text(size = 12),
axis.text = element_text(size = 10),
axis.text.x = element_text(angle = 90),
strip.text.x = element_text(size = 10))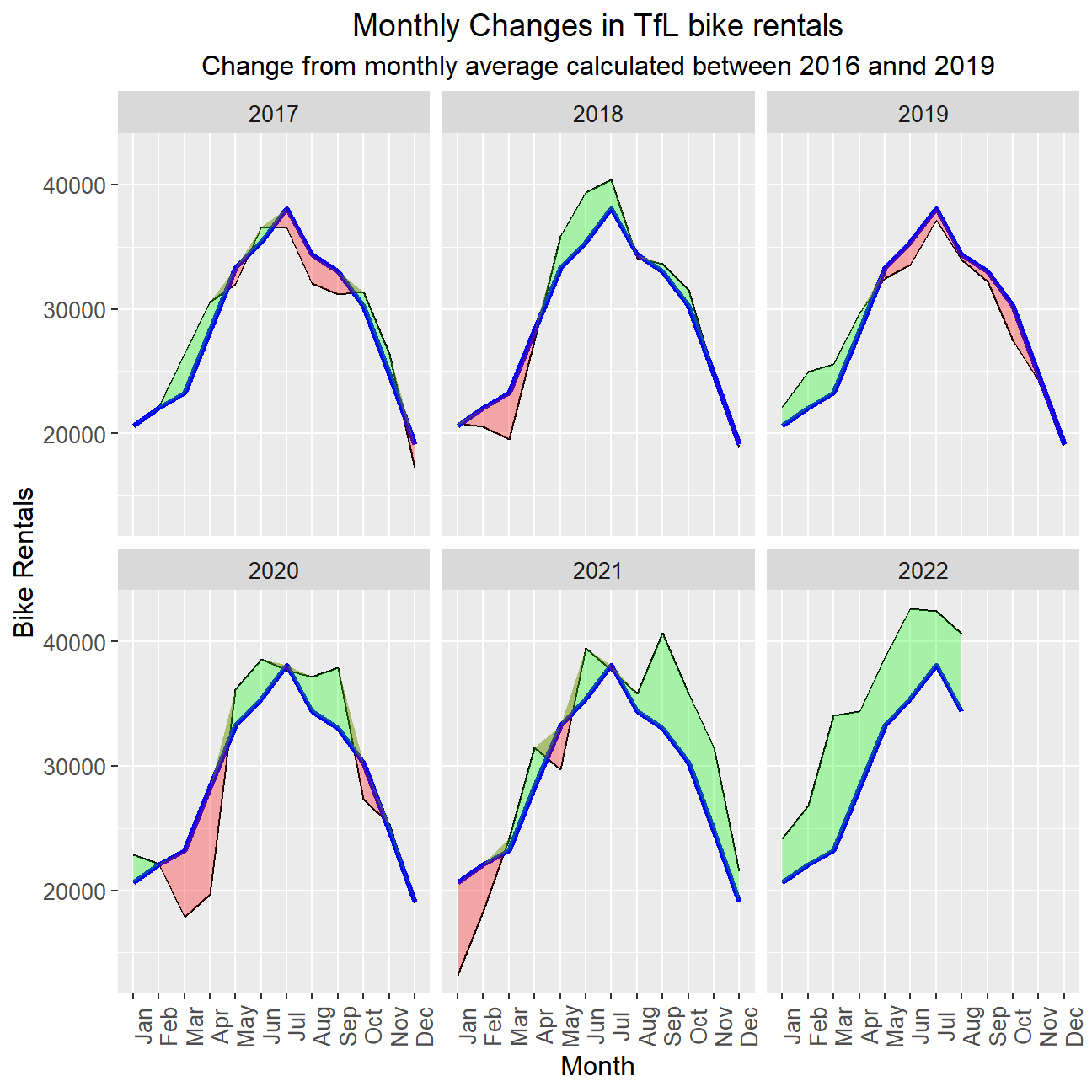
# Create expected weekly bike rental by averaging weekly data from 2016-2019
expected_weekly_rental_summary <- bike %>%
filter(year >= 2016 & year <= 2019) %>%
group_by(week) %>%
summarise(expected_rentals = mean(bikes_hired, na.rm = TRUE))
# Create actual weekly bike rental data from 2017-2022
weekly_summary_17_22 <- bike %>%
filter(year >= 2017) %>%
group_by(year, week) %>%
summarise(weekly_mean = mean(bikes_hired))
# Join both tables and create new column measuring weekly percent deviation
weekly_full_summary <- weekly_summary_17_22 %>%
left_join(y = expected_weekly_rental_summary, by = "week") %>%
mutate(percent_change_weekly = (weekly_mean/expected_rentals - 1) * 100) %>%
filter(!(week >= 52 & year == 2022))
#filter date anomalies (due to the way R defines week 52 and 53)
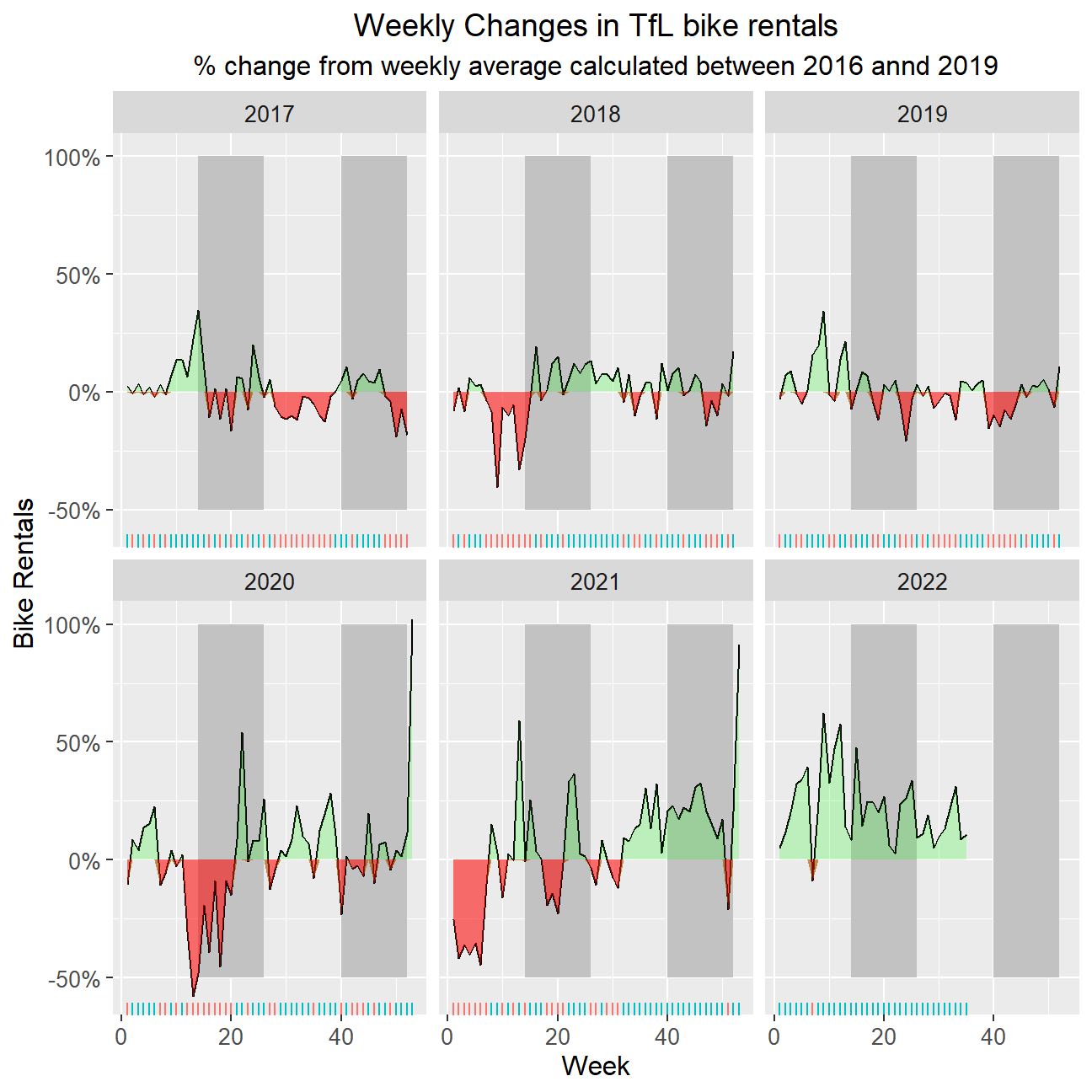
# Plot weekly percent deviation in bike rentals faceted on year
ggplot(weekly_full_summary, aes(x = week)) +
facet_wrap(~ year) +
geom_rect(aes(x = week, xmin = 14, xmax = 26, ymin = -50, ymax = 100), fill = "grey", alpha = 0.1) + #Create rectangle representing Q2
geom_rect(aes(x = week, xmin = 40, xmax = 52, ymin = -50, ymax = 100), fill = "grey", alpha = 0.1) + #Create rectangle representing Q4
geom_line(aes(y = percent_change_weekly), show.legend = FALSE) +
geom_ribbon(aes(ymin = 0, ymax = pmin(0,percent_change_weekly), alpha = 0.1), fill = "red", show.legend = FALSE) +
geom_ribbon(aes(ymin = percent_change_weekly, ymax = pmin(0,percent_change_weekly)), fill = "green", alpha = 0.2, show.legend = FALSE) + #Create ribbons
geom_rug(aes(colour = case_when(percent_change_weekly > 0 ~ "red",
percent_change_weekly < 0 ~ "green")),
sides = "b", show.legend = FALSE) + #Create rugs
scale_fill_manual(values=c("red", "green"), name="fill") + #Define rug colours
scale_y_continuous(labels = scales::percent_format(scale = 1)) +
labs(title = "Weekly Changes in TfL bike rentals", subtitle = "% change from weekly average calculated between 2016 annd 2019", x = "Week", y = "Bike Rentals") +
theme(plot.title = element_text(size = 14, hjust = 0.5),
plot.subtitle = element_text(size = 12, hjust = 0.5),
axis.title = element_text(size = 12),
axis.text = element_text(size = 10),
strip.text.x = element_text(size = 10))